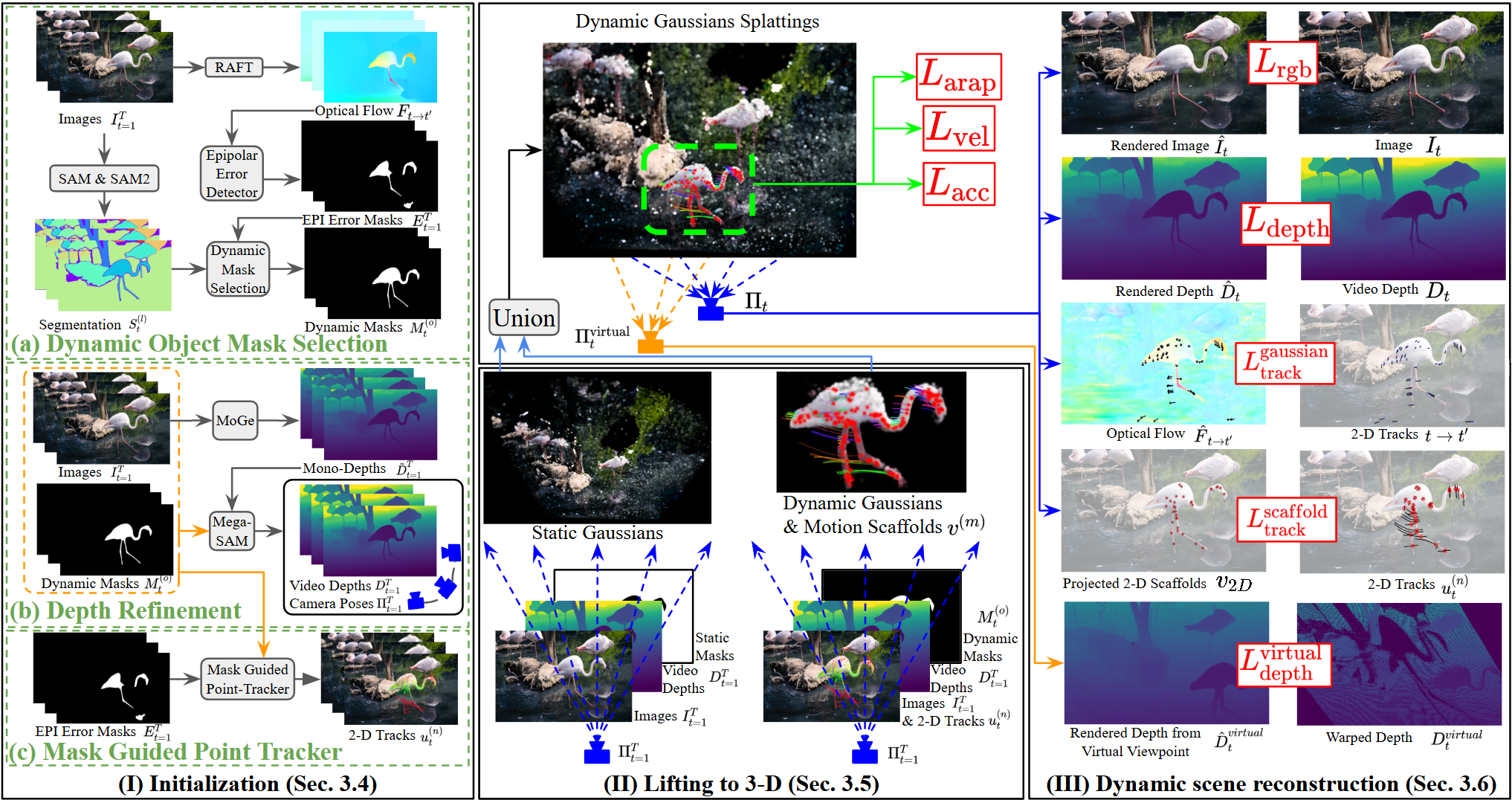
Method Overview
This work was supported by Lenovo and the UW Reality Lab.
@inproceedings{10.1145/3757377.3763910,
author = {Shih, Meng-Li and Chen, Ying-Huan and Liu, Yu-Lun and Curless, Brian},
title = {Prior-Enhanced Gaussian Splatting for Dynamic Scene Reconstruction from Casual Video},
year = {2025},
isbn = {9798400721373},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3757377.3763910},
doi = {10.1145/3757377.3763910},
abstract = {We introduce a fully automatic pipeline for dynamic scene reconstruction from casually captured monocular RGB videos. Rather than designing a new scene representation, we enhance the priors that drive Dynamic Gaussian Splatting. Video segmentation combined with epipolar-error maps yields object-level masks that closely follow thin structures; these masks (i) guide an object-depth loss that sharpens the consistent video depth, and (ii) support skeleton-based sampling plus mask-guided re-identification to produce reliable, comprehensive 2-D tracks. Two additional objectives embed the refined priors in the reconstruction stage: a virtual-view depth loss removes floaters, and a scaffold-projection loss ties motion nodes to the tracks, preserving fine geometry and coherent motion. The resulting system surpasses previous monocular dynamic scene reconstruction methods and delivers visibly superior renderings. Project page: https://priorenhancedgaussian.github.io/},
booktitle = {Proceedings of the SIGGRAPH Asia 2025 Conference Papers},
articleno = {74},
numpages = {13},
location = {
},
series = {SA Conference Papers '25}
}

